
这是三部分系列中的第二篇文章,它将提供对Go中调度程序背后的机制和语义的理解。本文重点介绍Go调度程序。
三部分系列的索引:
介绍
在本调度系列的第一部分中,我解释了操作系统调度程序的各个方面,我认为这些方面对于理解和理解Go调度程序的语义非常重要。在这篇文章中,我将在语义层面解释Go调度程序的工作原理并关注高级行为。Go调度程序是一个复杂的系统,小的机器上的细节并不重要。重要的是拥有良好的工作和行为方式。这将使你能够做出更好的工程决策。
你的计划开始
当你的Go程序启动时,它会为主机上标识的每个虚拟核心提供一个逻辑处理器(P)。如果你的处理器每个物理核心具有多个硬件线程(超线程),则每个硬件线程将作为虚拟核心呈现给你的Go程序。为了更好地理解这一点,请查看我的MacBook Pro的系统报告。

图1
你可以看到我有一个带有4个物理内核的处理器。本报告未公开的是每个物理核心的硬件线程数。英特尔酷睿i7处理器具有超线程功能,这意味着每个物理内核有2个硬件线程。这将向Go程序报告,8个虚拟核可用于并行执行操作系统线程。
要测试这一点,请考虑以下程序:
清单1
1 | package main |
当我在本地机器上运行该程序时,NumCPU()函数调用的结果将是值8.我在我的机器上运行的任何Go程序将被赋予8P。
每个P被分配一个操作系统线程(“M”)。’M’代表机器。该线程仍由操作系统管理,操作系统仍负责将线程放在核心上执行,如上一篇文章所述。这意味着当我在我的机器上运行Go程序时,我有8个线程可用于执行我的工作,每个线程都单独连接到P.
每个Go程序也都有一个初始的Goroutine(“G”),这是Go程序的执行路径。Goroutine本质上是一个Coroutine,但这是Go,所以我们用“G”代替字母“C”,我们得到了Goroutine这个词。你可以将Goroutines视为应用程序级线程,它们在很多方面类似于操作系统线程。正如操作系统线程在核心上下载上下文一样,Goroutines在上下文中打开和关闭。
最后一个难题是运行队列。Go调度程序中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)。每个P都有一个LRQ,用于管理指定在P的上下文中执行的Goroutines。这些Goroutines轮流在上下文中切换到分配给P的M。GRQ用于尚未分配给的Goroutines。还没有。有一个过程将Goroutines从GRQ转移到LRQ,我们将在后面讨论。
图2提供了所有这些组件的图像。
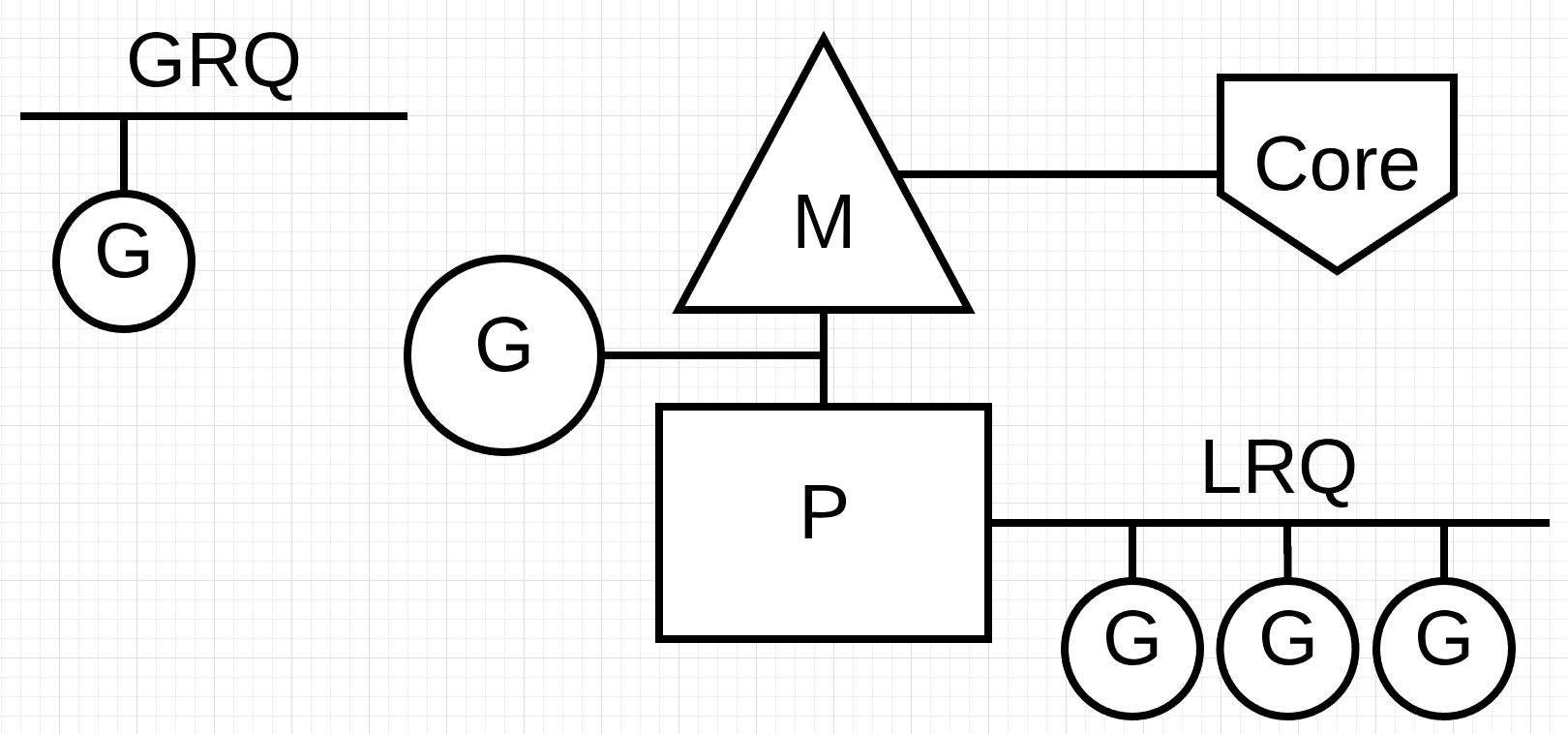
图2
协作调度程序
正如我们在第一篇文章中讨论的那样,操作系统调度程序是一个抢占式调度程序。从本质上讲,这意味着你无法预测调度程序在任何给定时间将要执行的操作。内核正在做出决策,一切都是非确定性的。运行在操作系统之上的应用程序无法控制内核中发生的事情,除非它们利用原子指令和互斥调用等同步原语。
Go调度程序是Go运行时的一部分,Go运行时内置在应用程序中。这意味着Go调度程序在内核之上的用户空间中运行。Go调度程序的当前实现不是抢占式调度程序,而是协作调度程序。作为协作调度程序意味着调度程序需要在代码中的安全点处发生的明确定义的用户空间事件以做出调度决策。
Go合作调度程序的优点在于它的表现和感觉先发制人。你无法预测Go调度程序将要执行的操作。这是因为这个合作调度程序的决策不是由开发人员掌握,而是在Go运行时。将Go调度程序视为抢占式调度程序非常重要,并且由于调度程序是非确定性的,因此这并不是一件容易的事。
Goroutine并发
就像线程一样,Goroutines拥有相同的三个高级状态。这些决定了Go调度程序在任何给定的Goroutine中所起的作用。Goroutine可以处于以下三种状态之一:Waiting,Runnable或Executing。
等待:这意味着Goroutine已停止并等待某些事情继续进行。这可能是出于等待操作系统(系统调用)或同步调用(原子操作和互斥操作)等原因。这些类型的延迟是性能不佳的根本原因。
可运行:这意味着Goroutine需要时间在M上,因此它可以执行其指定的指令。如果你有很多想要时间的Goroutines,那么Goroutines必须等待更长时间才能得到时间。此外,随着更多Goroutines争夺时间,任何给定的Goroutine获得的个人时间缩短了。这种类型的调度延迟也可能是性能不佳的原因。
执行:这意味着Goroutine已被置于M并正在执行其指令。与应用程序相关的工作即将完成。这是每个人都想要的。
上下文切换
Go调度程序需要明确定义的用户空间事件,这些事件发生在代码中的安全点以进行上下文切换。这些事件和安全点在函数调用中表现出来。函数调用对Go调度程序的运行状况至关重要。今天(使用Go 1.11或更低版本),如果运行任何未进行函数调用的紧密循环,则会导致调度程序和垃圾回收中的延迟。函数调用在合理的时间范围内发生是至关重要的。
注意:有一个1.12 的提议被接受在Go调度程序中应用非协作抢占技术,以允许抢占紧密循环。
Go程序中发生了四类事件,允许调度程序做出调度决策。这并不意味着它总是会发生在其中一个事件上。这意味着调度程序获得了机会。
- 使用关键字 go
- 垃圾收集
- 系统调用
- 同步和编排
使用关键字 go
关键字go是你创建Goroutines的方式。一旦创建了新的Goroutine,它就为调度程序提供了做出调度决策的机会。
垃圾收集
由于GC使用自己的Goroutines运行,因此那些Goroutines需要时间在M上运行。这会导致GC产生大量的调度混乱。但是,调度程序非常聪明地了解Goroutine正在做什么,它将利用这些智能做出明智的决策。一个聪明的决定是上下文切换一个Goroutine,它想要在GC期间接触那些没有接触堆的堆。当GC运行时,正在做出许多调度决策。
系统调用
如果Goroutine进行系统调用会导致Goroutine阻塞M,有时调度程序能够将Goroutine从M上下文切换并将新的Goroutine上下文切换到相同的M.但是,有时新的M是需要继续执行在P中排队的Goroutines。如何工作将在下一节中更详细地解释。
同步和编排
当你运行的操作系统具有异步处理系统调用的能力时,可以使用称为网络轮询器的内容来更有效地处理系统调用。这是通过在这些相应的操作系统中使用kqueue(Mac操作系统),epoll(Linux)或iocp(Windows)来实现的。
基于网络的系统调用可以由我们今天使用的许多操作系统异步处理。这是网络轮询器获得其名称的地方,因为它的主要用途是处理网络操作。通过使用网络轮询器进行网络系统调用,调度程序可以防止Goroutines在进行系统调用时阻止M. 这有助于保持M可用于在P的LRQ中执行其他Goroutines而无需创建新的Ms.这有助于减少操作系统上的调度负载。
查看其工作原理的最佳方法是运行示例。
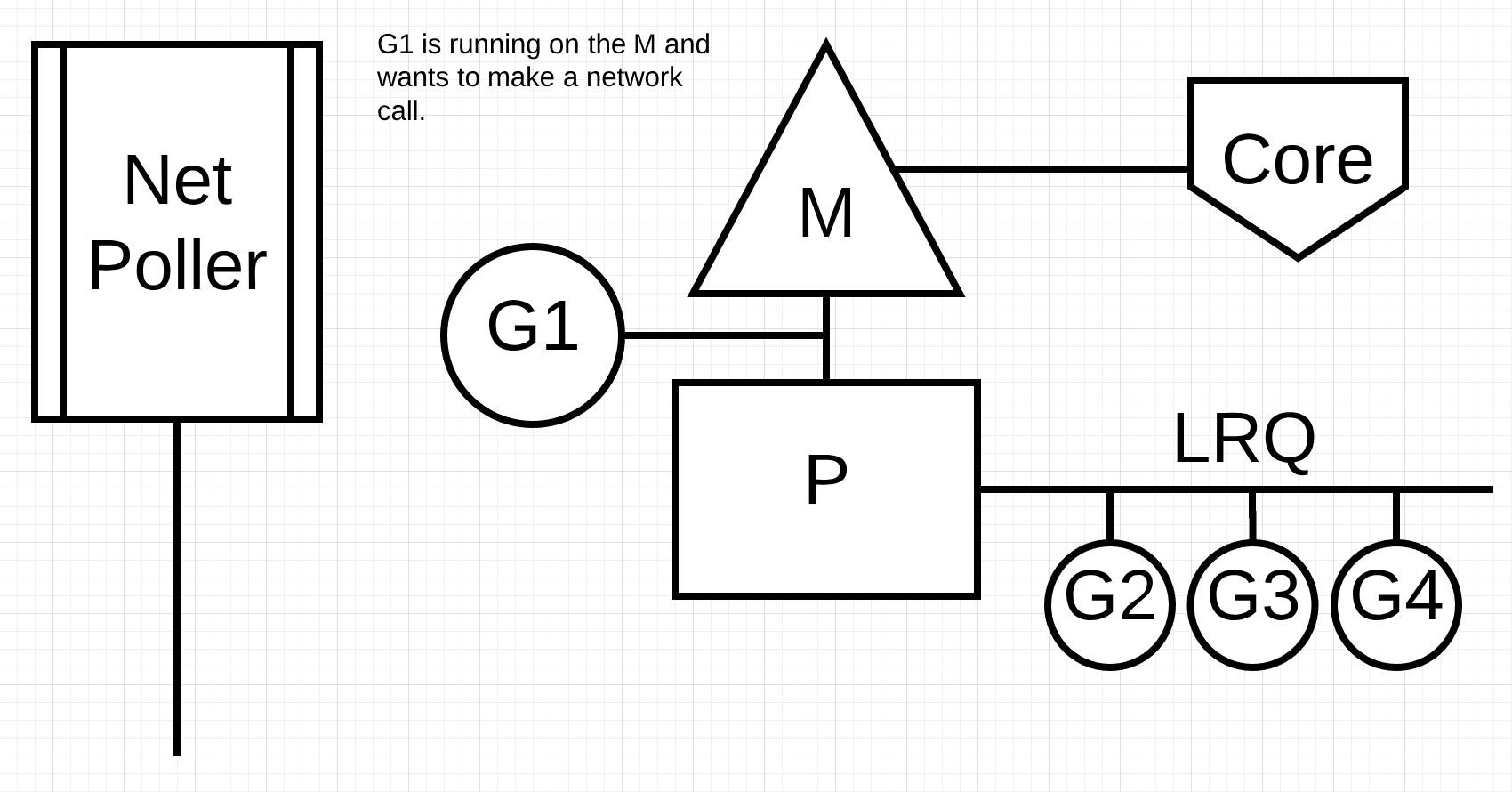
图3
图3显示了我们的基本调度图。Goroutine-1正在M上执行,并且还有3个Goroutines等待LRQ在M上等待。网络轮询器无所事事。
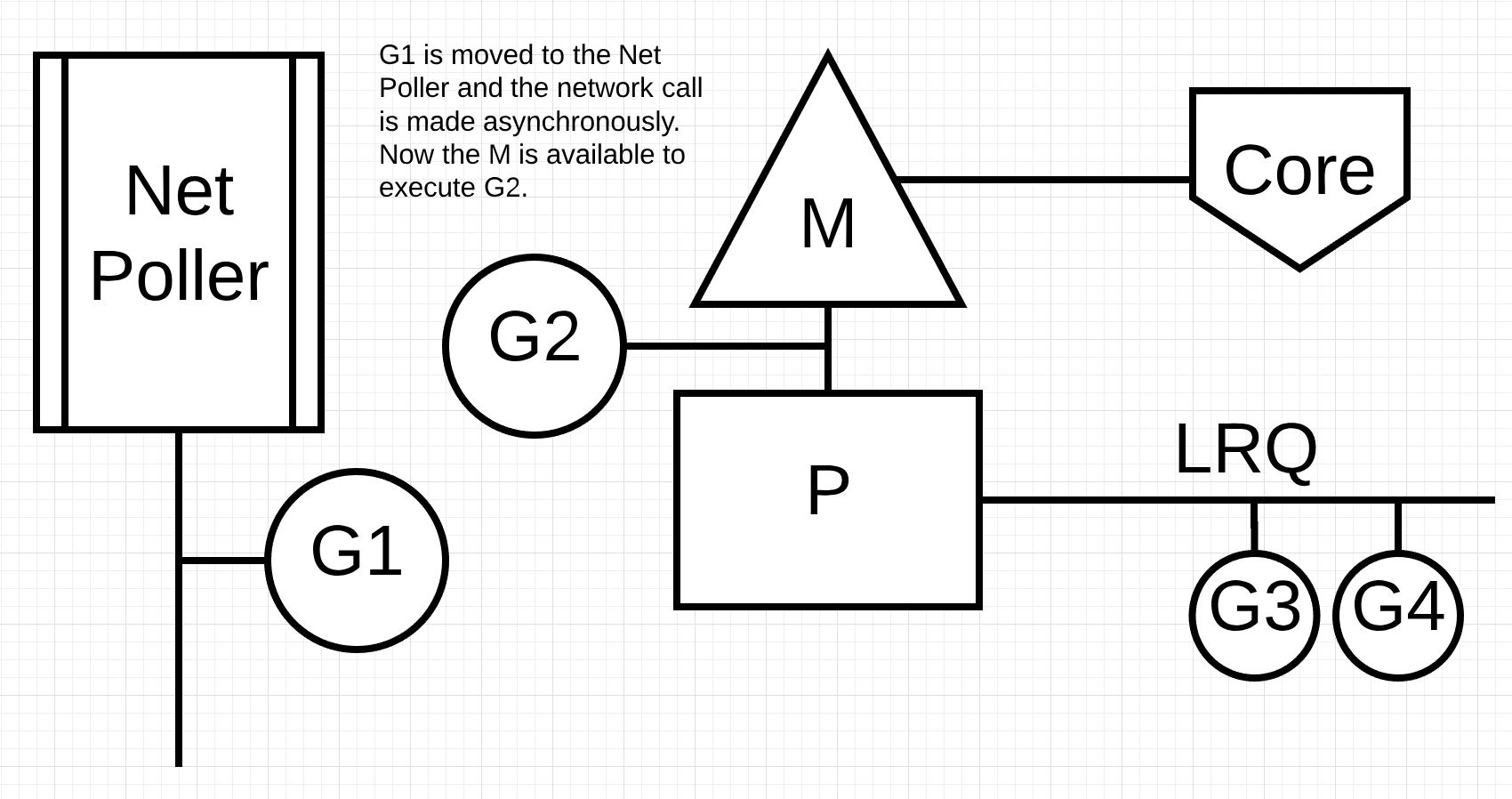
图4
在图4中,Goroutine-1想要进行网络系统调用,因此Goroutine-1被移动到网络轮询器并处理异步网络系统调用。一旦Goroutine-1移动到网络轮询器,M现在可以从LRQ执行不同的Goroutine。在这种情况下,Goroutine-2在M.上下文切换。
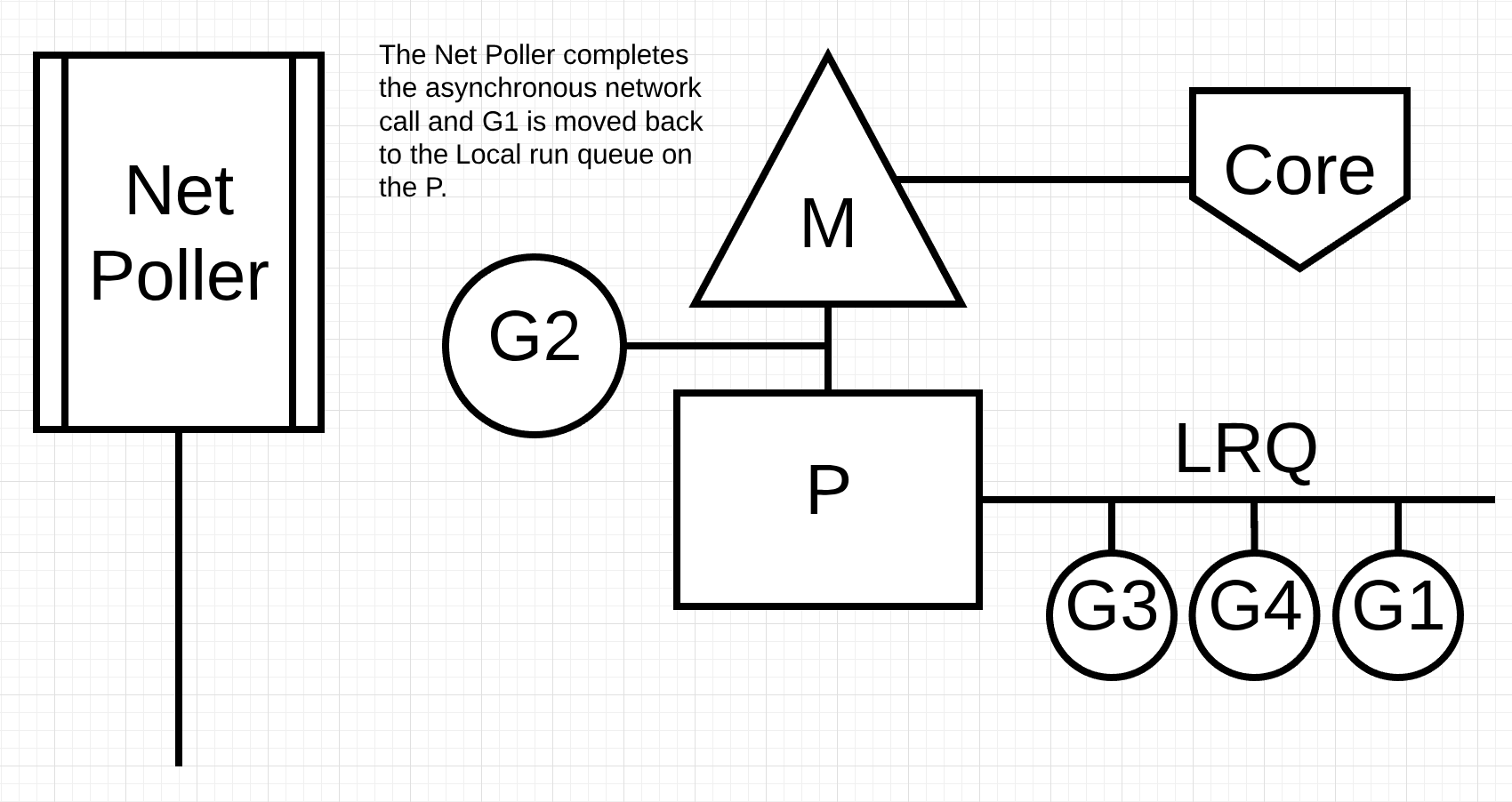
图5
在图5中,异步网络系统调用由网络轮询器完成,Goroutine-1被移回到L的LRQ中。一旦Goroutine-1可以在M上进行上下文切换,Go负责的Go相关代码可以再次执行。这里的最大优势是,要执行网络系统调用,不需要额外的Ms。网络轮询器具有操作系统线程,它正在处理有效的事件循环。
同步系统调用
当Goroutine想要进行无法异步完成的系统调用时会发生什么?在这种情况下,网络轮询器不能被使用,并且进行系统调用的Goroutine将阻止M.这是不幸的,但是没有办法防止这种情况发生。不能异步进行的系统调用的一个示例是基于文件的系统调用。如果你正在使用CGO,则可能还有其他情况,调用C函数也会阻止M.
注意:Windows操作系统确实能够异步进行基于文件的系统调用。从技术上讲,在Windows上运行时,可以使用网络轮询器。
让我们来看看同步系统调用(如文件I / O)会导致M阻塞的情况。
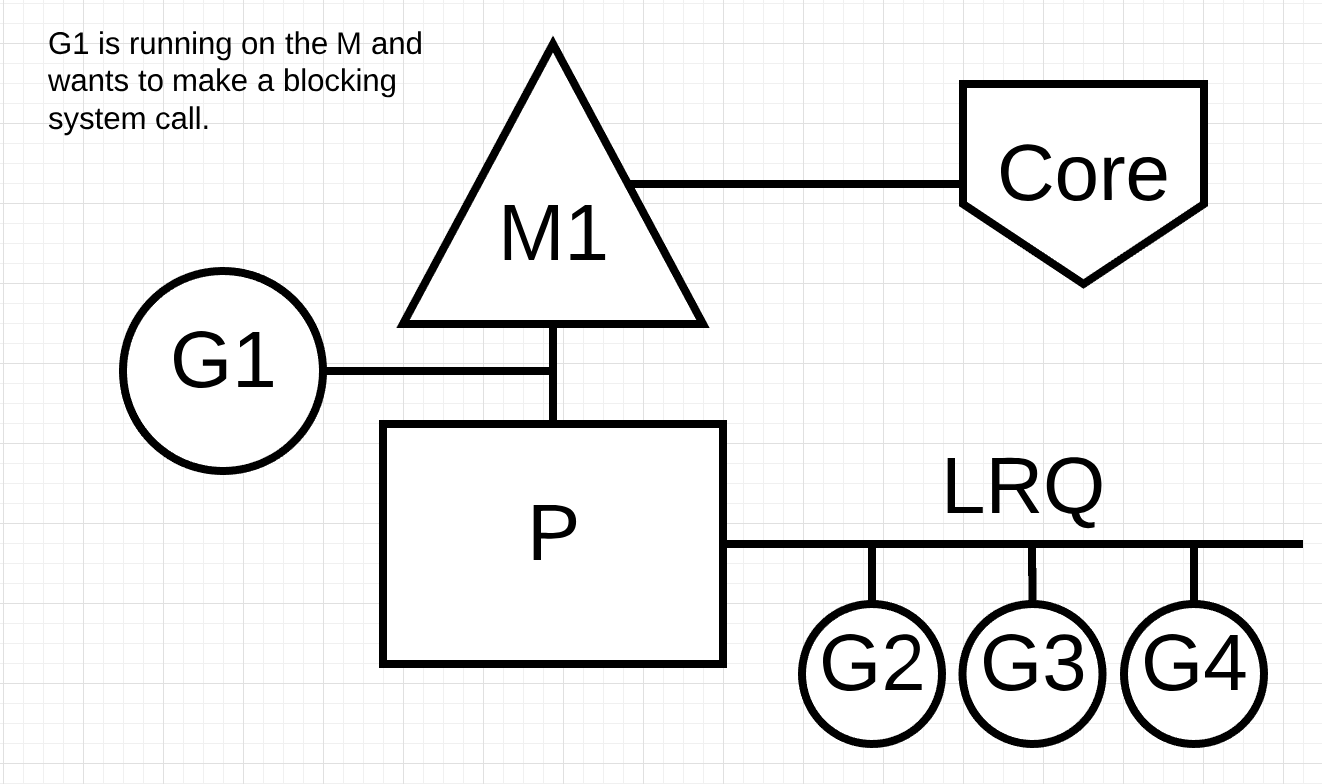
图6
图6再次显示了我们的基本调度图,但这次Goroutine-1将进行同步系统调用以阻止M1。
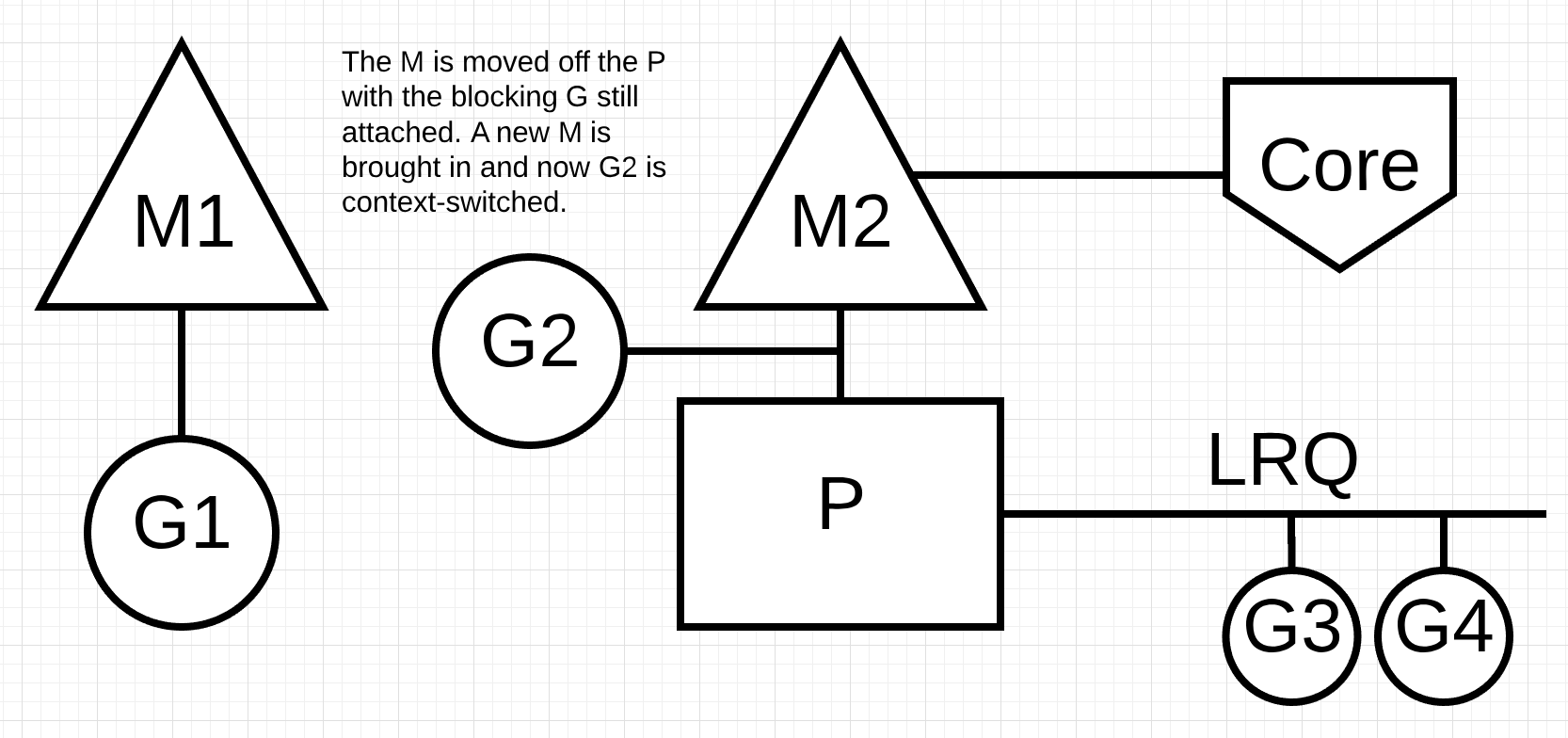
图7
在图7中,调度程序能够识别Goroutine-1已导致M阻塞。此时,调度程序将M1与P分离,同时仍然附加阻塞Goroutine-1。然后调度器引入新的M2来为P服务。此时,可以从LRQ中选择Goroutine-2并且在M2上进行上下文切换。如果由于之前的交换而已经存在M,则此切换比必须创建新M更快。
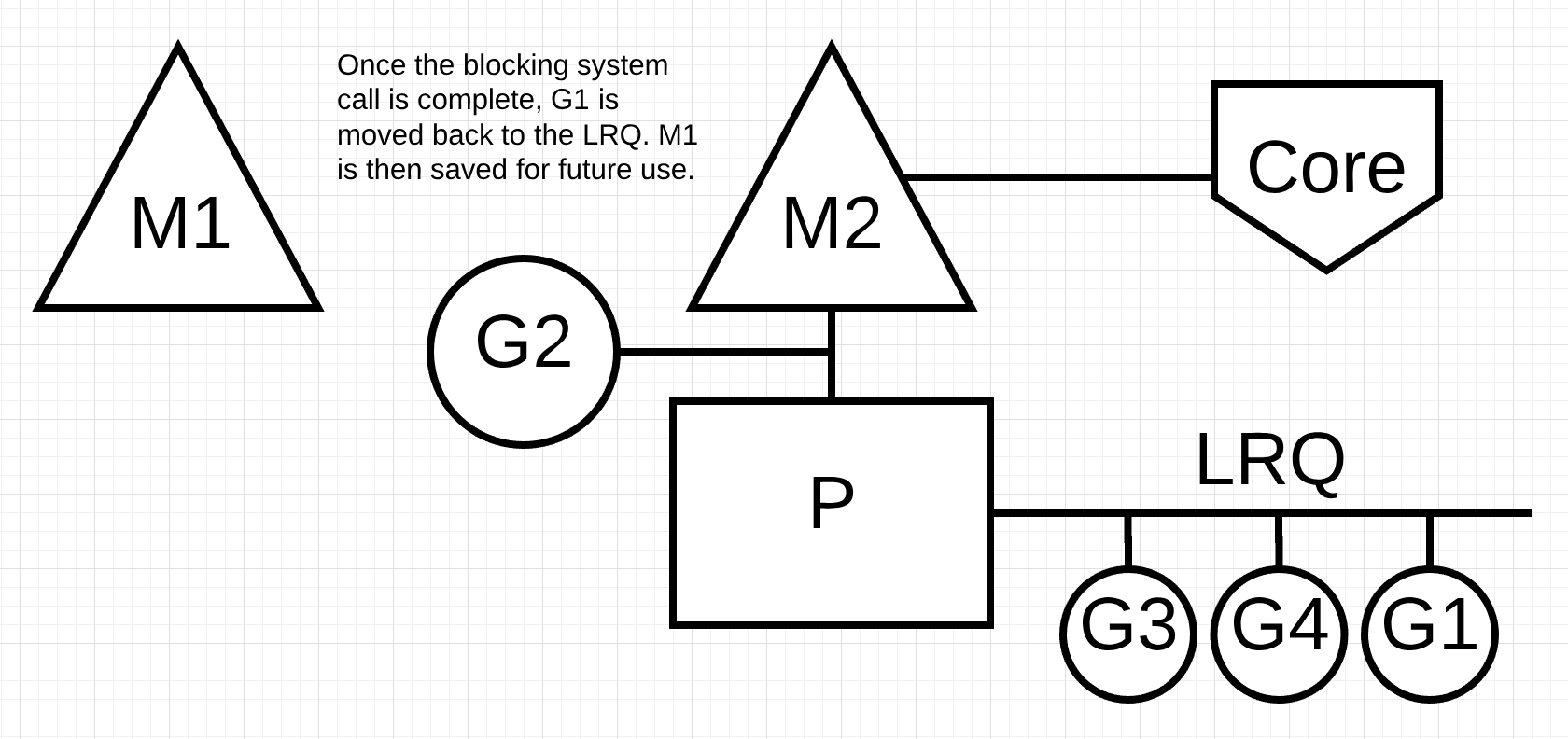
图8
在图8中,由Goroutine-1完成的阻塞系统调用完成。此时,Goroutine-1可以移回LRQ并再次由P服务。如果需要再次发生这种情况,则将M1放在侧面以备将来使用。
工作窃取
调度程序的另一个方面是它是一个工作窃取调度程序。这有助于在一些领域保持有效的调度。首先,你想要的最后一件事就是M进入等待状态,因为一旦发生这种情况,操作系统就会将M从核心上下文切换。这意味着即使有一个Goroutine处于可运行状态,P也无法完成任何工作,直到M在核心上进行上下文切换。窃取工作也有助于平衡所有P的Goroutines,从而更好地分配工作并更有效地完成工作。
让我们来看一个例子。
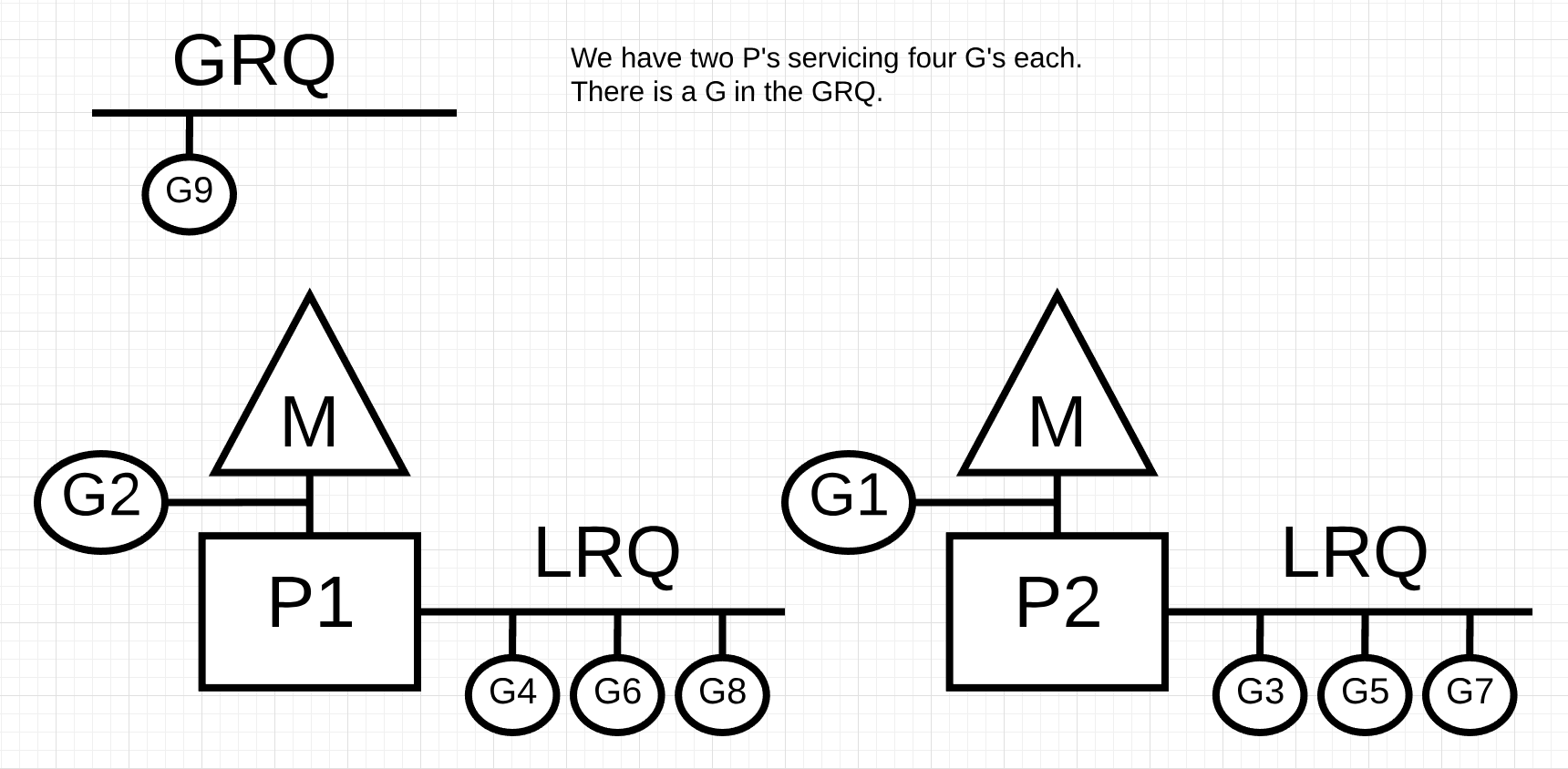
图9
在图9中,我们有一个多线程Go程序,其中两个P服务四个Goroutines,每个服务GRQ中有一个Goroutine。如果P的所有Goroutines中的一个服务很快就会发生什么?
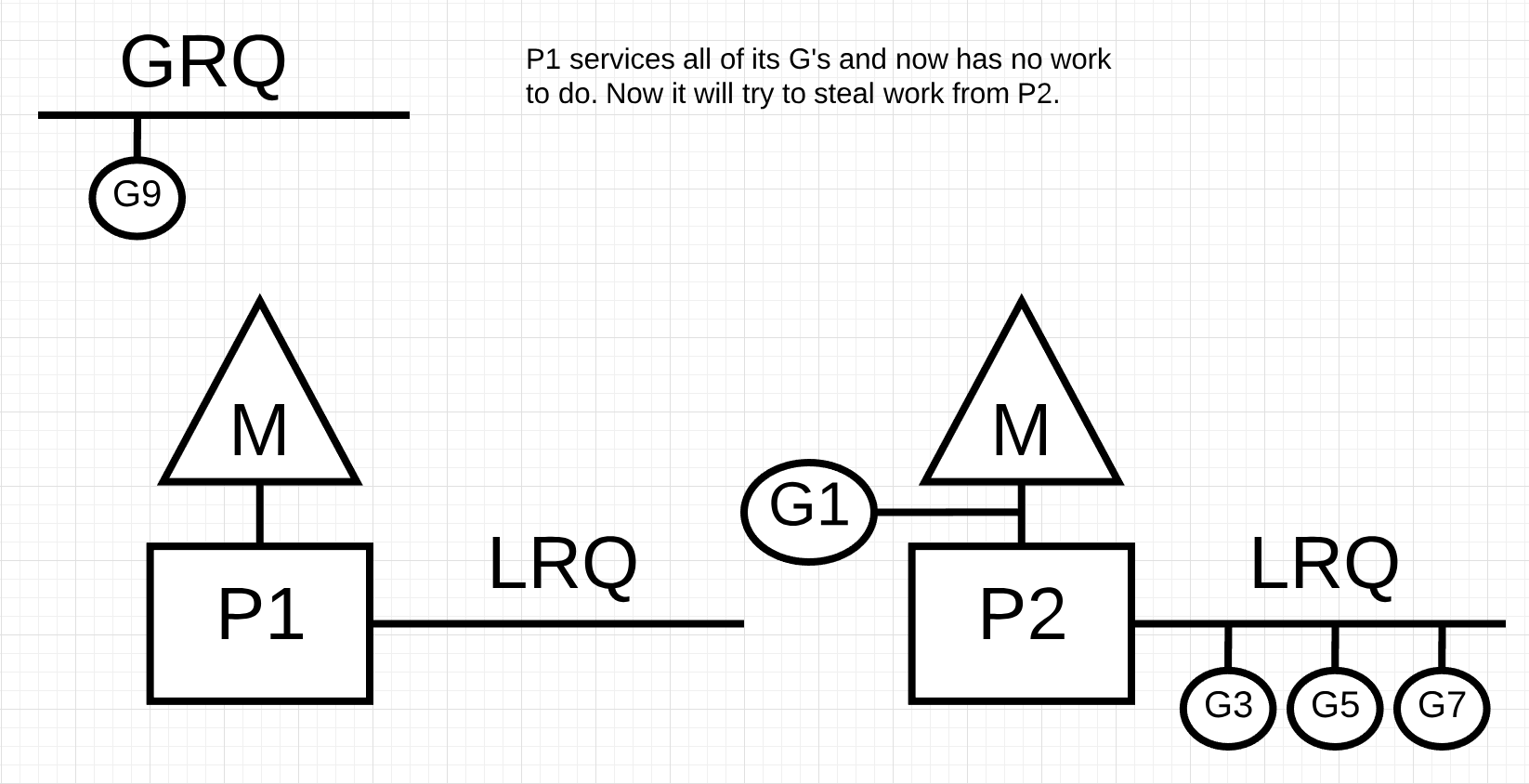
图10
在图10中,P1没有更多的Goroutines来执行。但是Goroutines处于可运行状态,无论是在LRQ中还是在GRQ中。这是P1需要偷工作的时刻。窃取工作的规则如下。
清单2
1 | runtime.schedule() { |
因此,基于清单2中的这些规则,P1需要在其LRQ中检查P2 for Goroutines并获取其发现的一半。
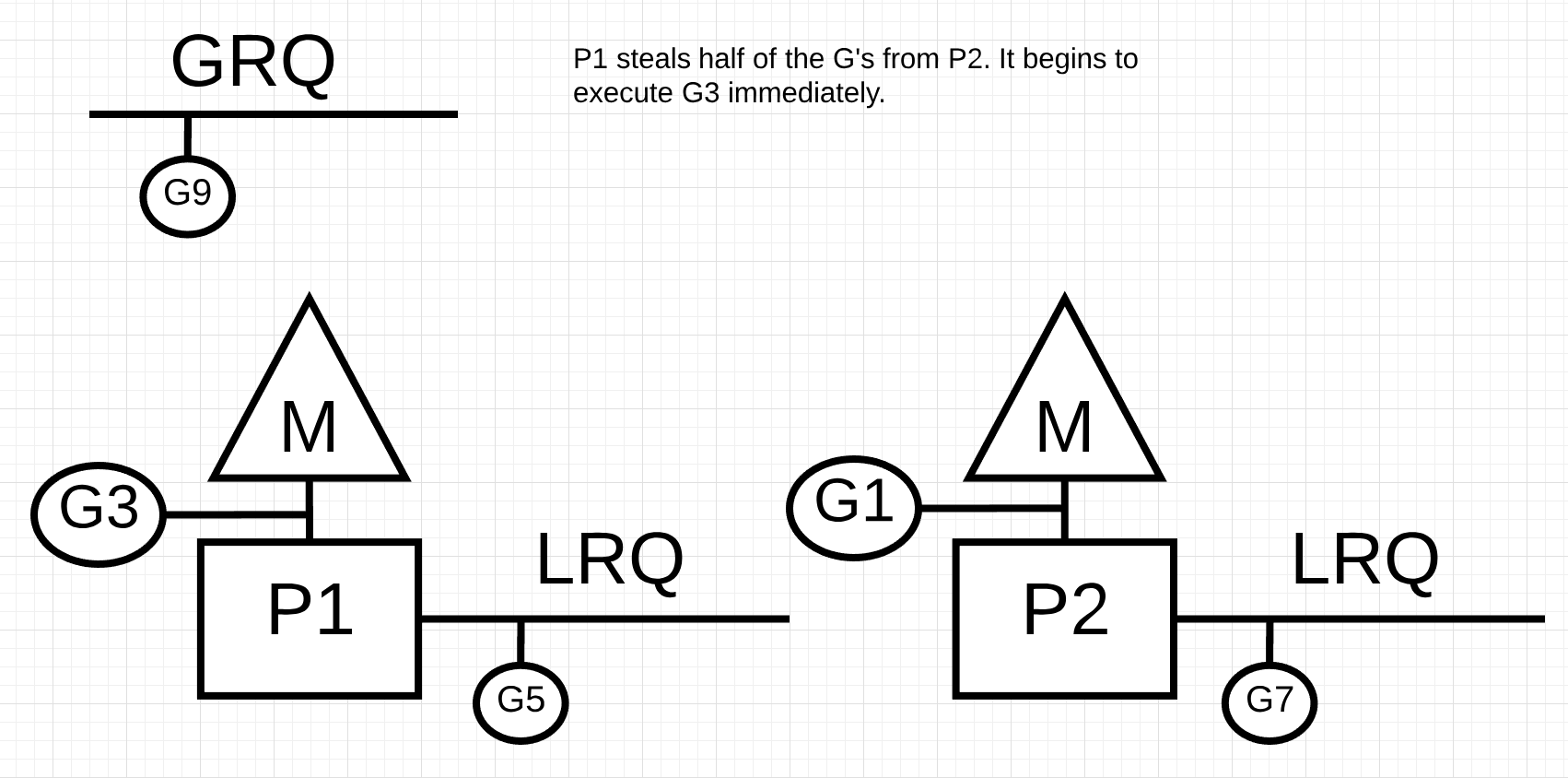
图11
在图11中,Goroutines的一半来自P2,现在P1可以执行那些Goroutines。
如果P2完成为其所有Goroutines提供服务并且P1的LRQ中没有任何东西会发生什么?
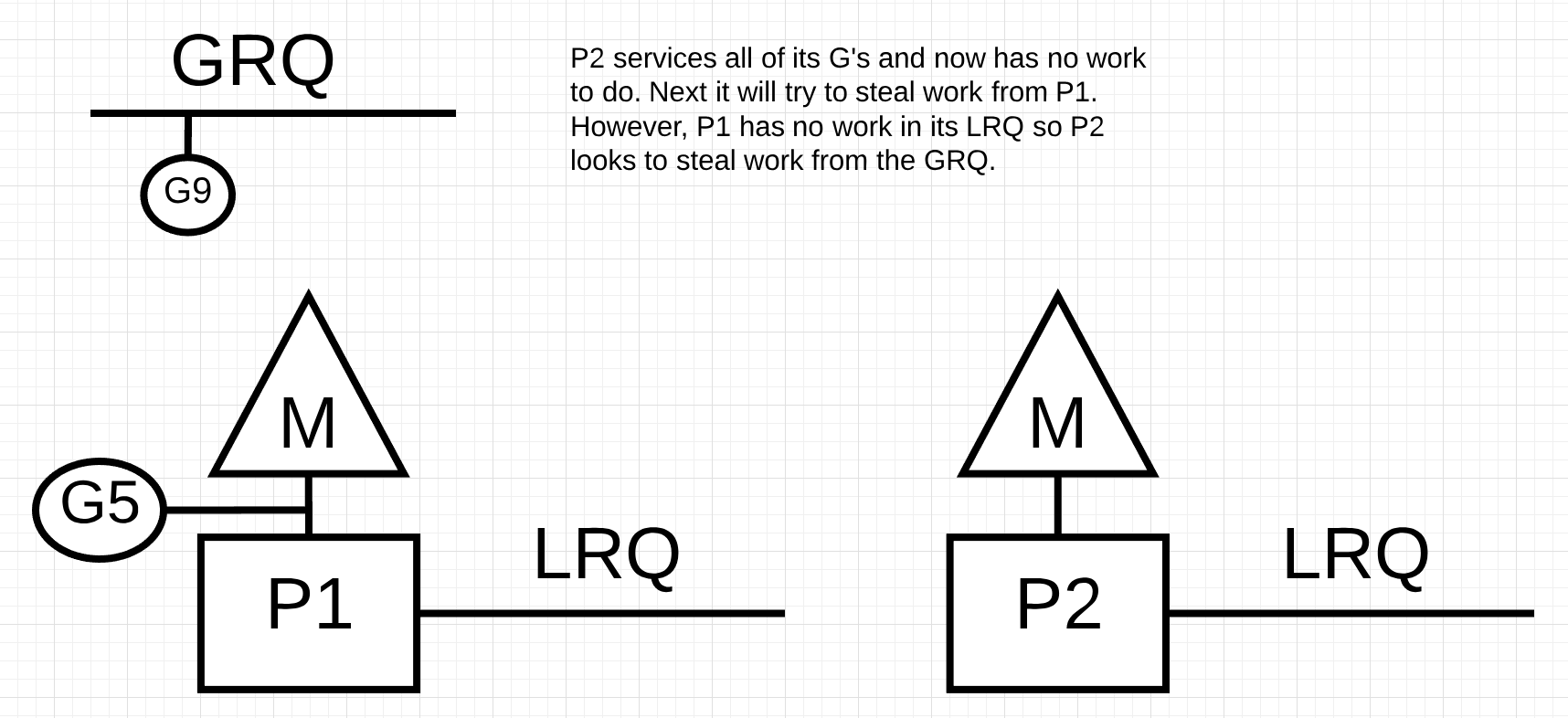
图12
在图12中,P2完成了所有工作,现在需要窃取一些。首先,它将查看P1的LRQ,但它不会找到任何Goroutines。接下来,它将查看GRQ。那里会发现Goroutine-9。
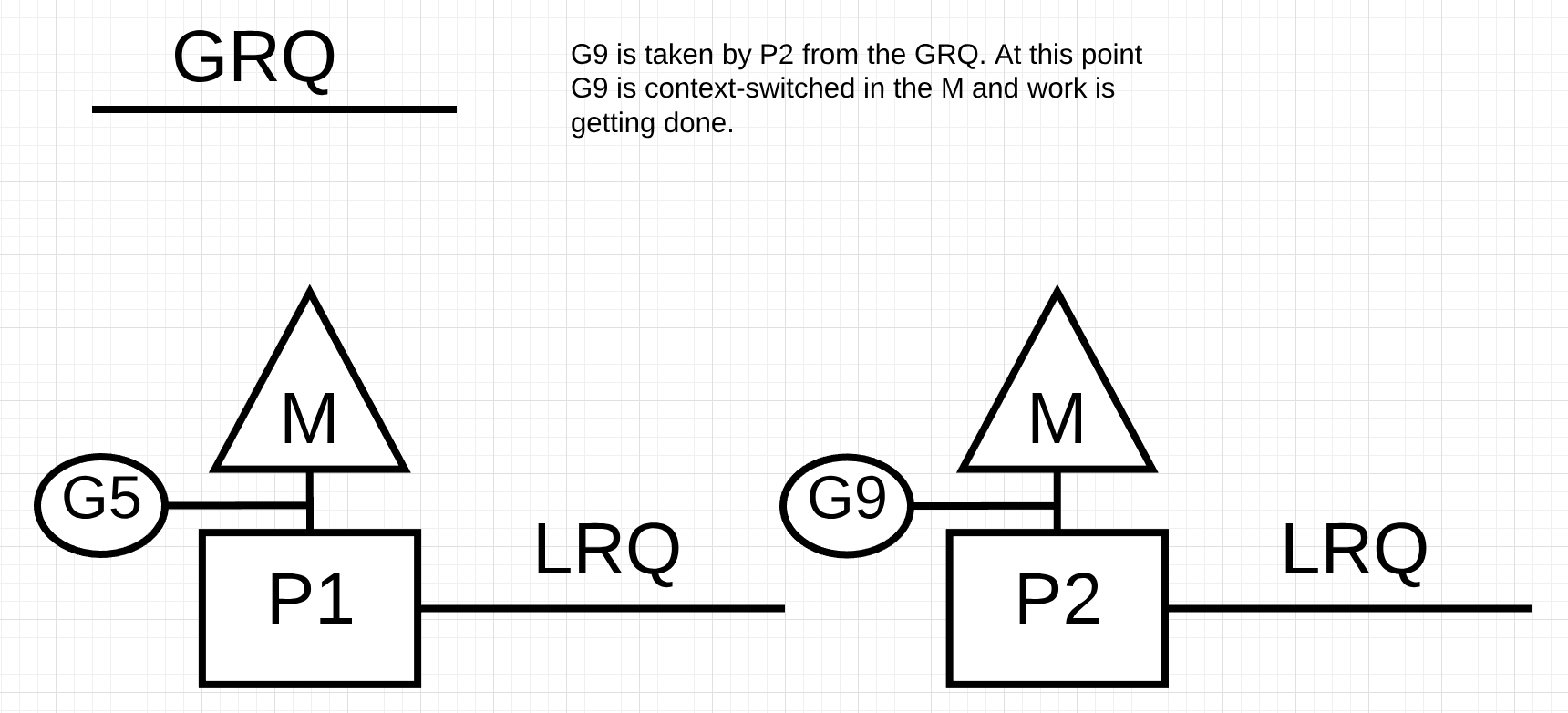
图13
在图13中,P2从GRQ窃取了Goroutine-9并开始执行工作。所有这些偷窃工作的好处在于它允许女士保持忙碌而不会闲着。这项工作窃取在内部被视为旋转M.这种旋转具有JBD在她的工作窃取博客文章中解释得很好的其他好处。
实际例子
有了相应的机制和语义,我想向你展示如何将所有这些结合在一起,以便Go调度程序随着时间的推移执行更多工作。想象一下用C编写的多线程应用程序,其中程序管理两个操作系统线程,它们相互传递消息。
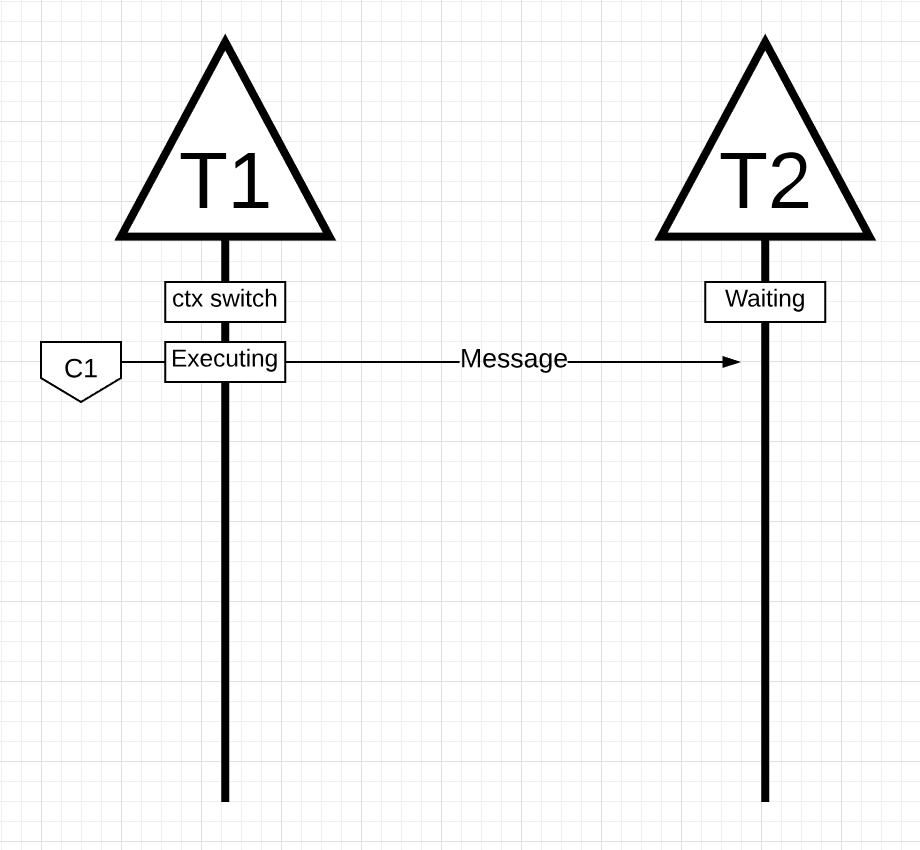
图14
在图14中,有2个线程来回传递消息。线程1在Core 1上进行上下文切换,现在正在执行,这允许线程1将其消息发送到线程2。
注意:消息的传递方式并不重要。当业务流程继续进行时,重要的是线程的状态。
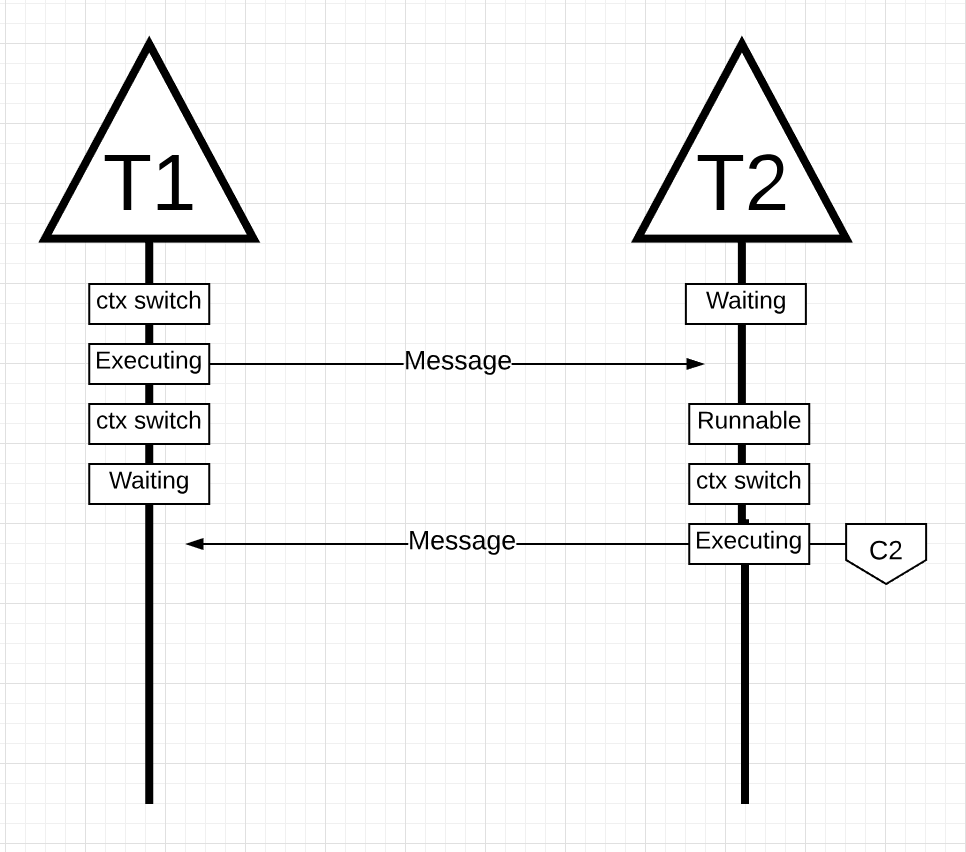
图15
在图15中,一旦线程1完成发送消息,它现在需要等待响应。这将导致线程1从Core 1上下文关闭并进入等待状态。一旦线程2收到有关该消息的通知,它就会进入可运行状态。现在操作系统可以执行上下文切换并在Core上执行线程2,它恰好是Core 2.接下来,线程2处理消息并将新消息发送回线程1。
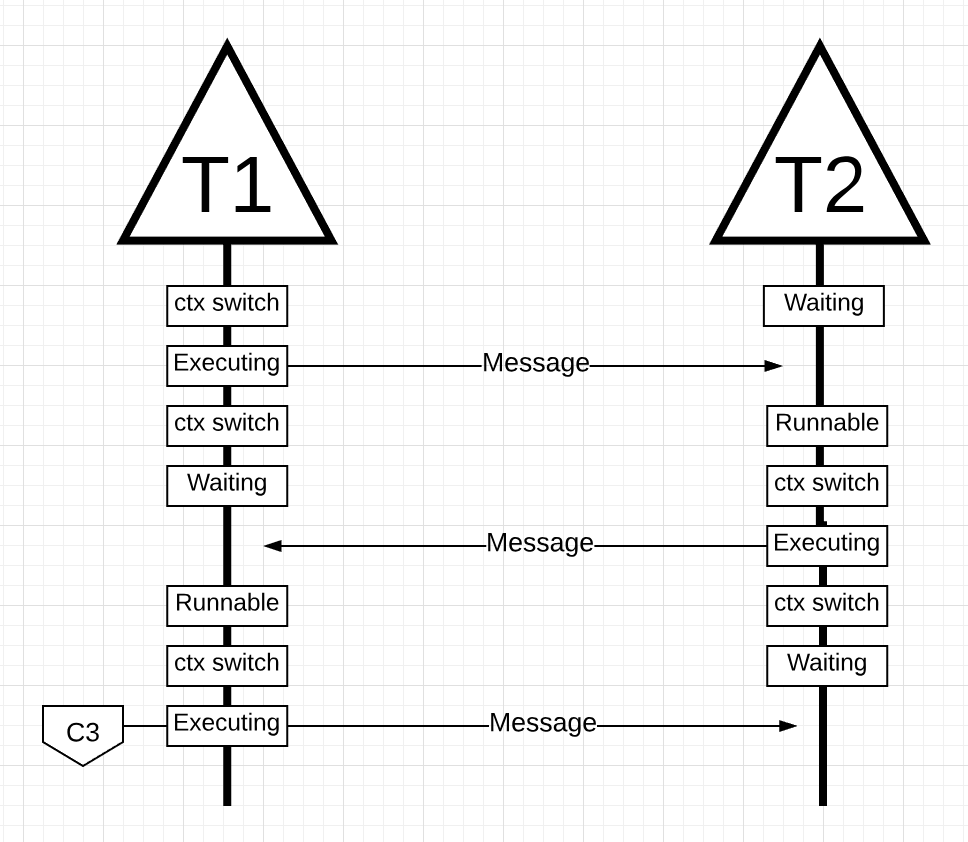
图16
在图16中,线程上下文切换再次由线程2接收线程2的消息。现在线程2上下文 - 从执行状态切换到等待状态和线程1上下文 - 从等待状态切换到可运行状态最后回到执行状态,允许它处理并发回新消息。
所有这些上下文切换和状态更改都需要时间来执行,这限制了工作的完成速度。由于每个上下文切换可能会产生约1000纳秒的延迟,并且希望硬件每纳秒执行12条指令,因此你可以查看12k指令,或多或少,在这些上下文切换期间不执行。由于这些线程也在不同的核心之间弹跳,因高速缓存行未命中而导致额外延迟的可能性也很高。
让我们采用相同的例子,但使用Goroutines和Go调度程序。
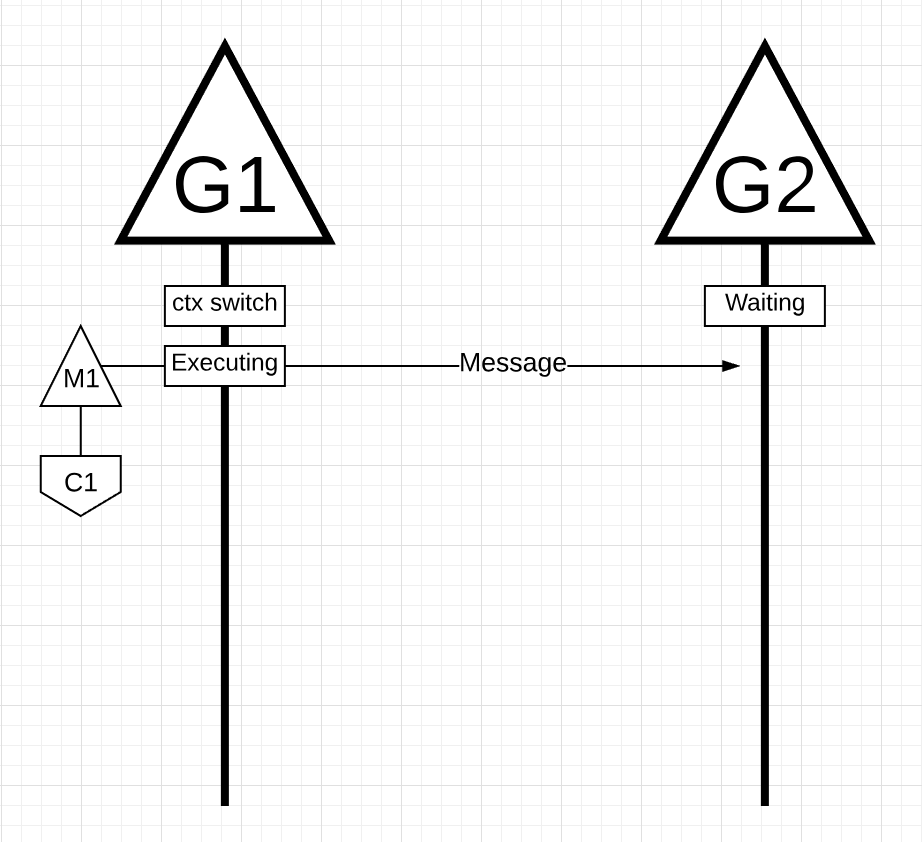
图17
在图17中,有两个Goroutine正在编排,彼此之间来回传递消息。G1在M1上进行上下文切换,这恰好在Core 1上运行,这允许G1执行其工作。G1的工作是将其消息发送给G2。
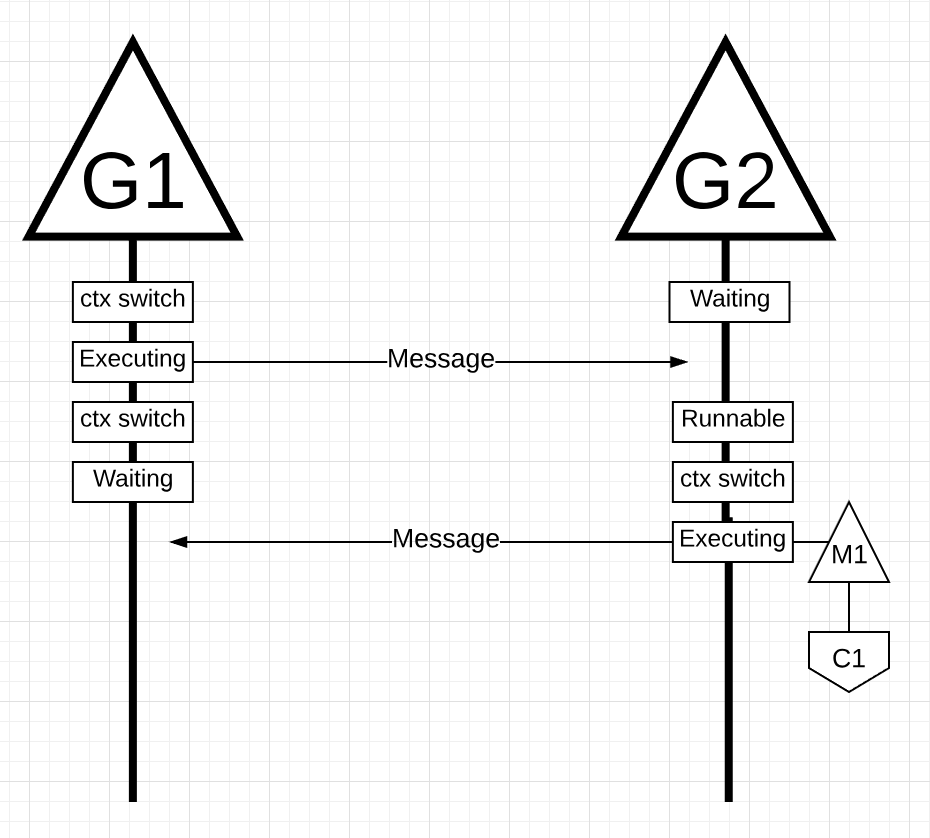
图18
在图18中,一旦G1完成发送消息,它现在需要等待响应。这将导致G1上下文关闭M1并进入等待状态。一旦G2收到有关该消息的通知,它就会进入可运行状态。现在,Go调度程序可以执行上下文切换并在M1上执行G2,M1仍然在Core 1上运行。接下来,G2处理消息并将新消息发送回G1。
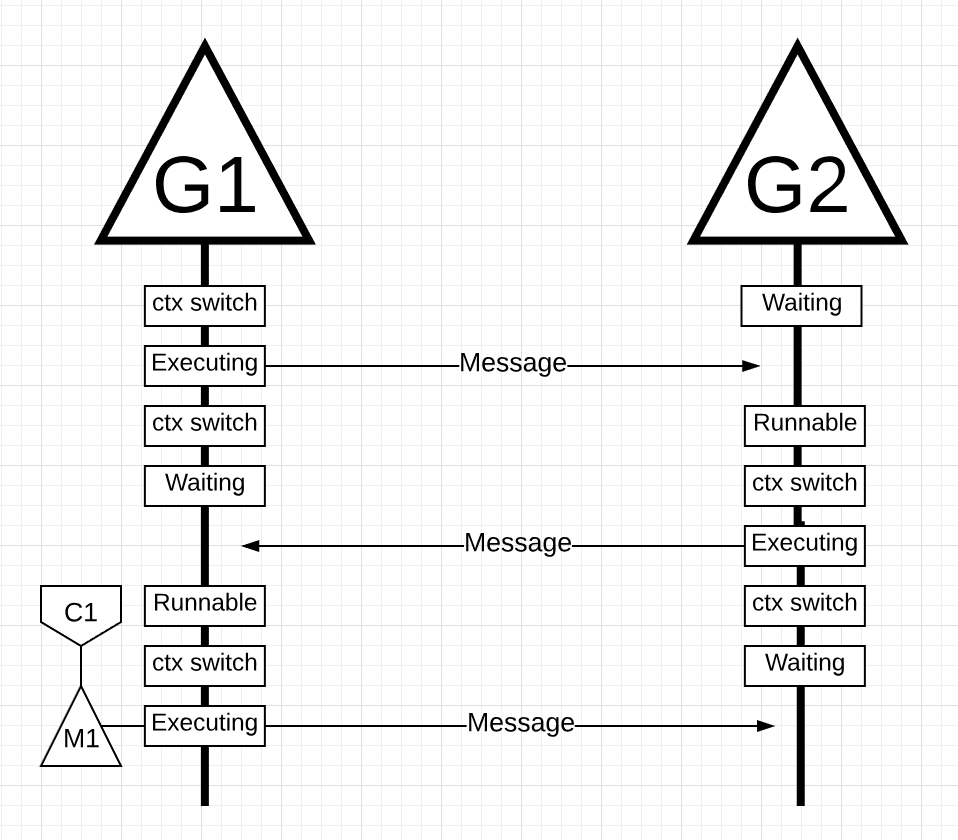
图19
在图19中,当G2接收到由G2发送的消息时,事物再次上下文切换。现在G2上下文 - 从执行状态切换到等待状态,G1上下文 - 从等待状态切换到可运行状态,最后返回到执行状态,这允许它处理并发回新消息。
表面上的事情似乎没有任何不同。无论你使用线程还是Goroutines,都会发生所有相同的上下文切换和状态更改。但是,使用线程和Goroutines之间存在一个主要区别,乍一看可能并不明显。
在使用Goroutines的情况下,相同的操作系统线程和核心用于所有处理。这意味着,从操作系统的角度来看,操作系统线程永远不会进入等待状态; 不止一次。因此,在使用Goroutines时,使用Threads时我们丢失到上下文切换的所有指令都不会丢失。
从本质上讲,Go已将IO / Blocking工作转变为操作系统级别的CPU限制工作。由于所有上下文切换都是在应用程序级别进行的,因此在使用Threads时,每个上下文切换都不会丢失相同的~12k指令(平均)。在Go中,那些相同的上下文切换花费大约200纳秒或~2.4k指令。调度程序还有助于提高缓存线效率和NUMA。这就是为什么我们不需要比虚拟核心更多的线程。在Go中,随着时间的推移,可以完成更多的工作,因为Go调度程序尝试使用更少的线程并在每个线程上执行更多操作,这有助于减少操作系统和硬件的负载。
结论
Go调度程序在设计如何考虑操作系统和硬件如何工作的复杂性方面确实令人惊讶。在操作系统级别将IO /阻塞工作转换为CPU限制工作的能力是我们在利用更多CPU容量的过程中获得巨大成功的地方。这就是为什么你不需要比虚拟核心更多的操作系统线程。你可以合理地期望每个虚拟核心只需一个操作系统线程即可完成所有工作(CPU和阻塞IO绑定)。对于不需要阻止操作系统线程的系统调用的网络应用程序和其他应用程序,可以这样做。
作为开发人员,你仍然需要了解你的应用在你正在处理的工作类型方面正在做什么。你无法创建无限数量的Goroutines并期望惊人的性能。少总是更多,但是通过理解这些Go-scheduler语义,你可以做出更好的工程决策。在下一篇文章中,我将探讨以保守方式利用并发性以获得更好性能的想法,同时仍然平衡可能需要添加到代码中的复杂性。
原文:
1) Scheduling In Go : Part I - 操作系统 Scheduler
2) Scheduling In Go : Part II - Go Scheduler
3) Scheduling In Go : Part III - Concurrency

